Background: Determining the right sample size is extremely important, and often times more complex when you dive into the specifics. In any type of testing you conduct, the correct sample size depends on a number of factors.
You’ll often hear that a sample size of n = 30 should be your minimum target. This should be understood that you need 30 minimum samples before you can expect a z-test analysis (normal distribution) to be valid. A z-test is used in hypothesis testing to evaluate whether a finding or association is statistically significant or not . This rationale comes from the Central Limit Theorem to approximate the sample distributions.
As a general rule of thumb from Anna-Katrina Shedletsky’s article:
Except in extreme situations, any answer that is less than five or more than 100 is probably wrong.
To be clear, the reasoning behind your sampling size is more important than the number itself, but the rule of thumb above works well. Generally speaking, this depends on. depends on:
- Type of Data Collected (Attribute-Pass/Fail, Variable-Continuous data that can be collected)
- Desired Confidence Interval: Overall degree of certainty/uncertainty in a sampling method
- Reliability: Overall consistency of a measure
- Use-Case Scenario: Is this a critical part you’re testing, or just a test conducted for preliminary validation? This will change how tight the confidence/reliability parameters are.
To distinguish even further between reliability and confidence, reliability is a measure of how well a product performs under a certain set of conditions in a given time frame, while confidence is the minimum certainty that your failure rate is accurate.
Without diving too deep into the equations, here’s a good reference in terms of determining the rough sample size based on your confidence level, desired reliability percentage, and type of data:
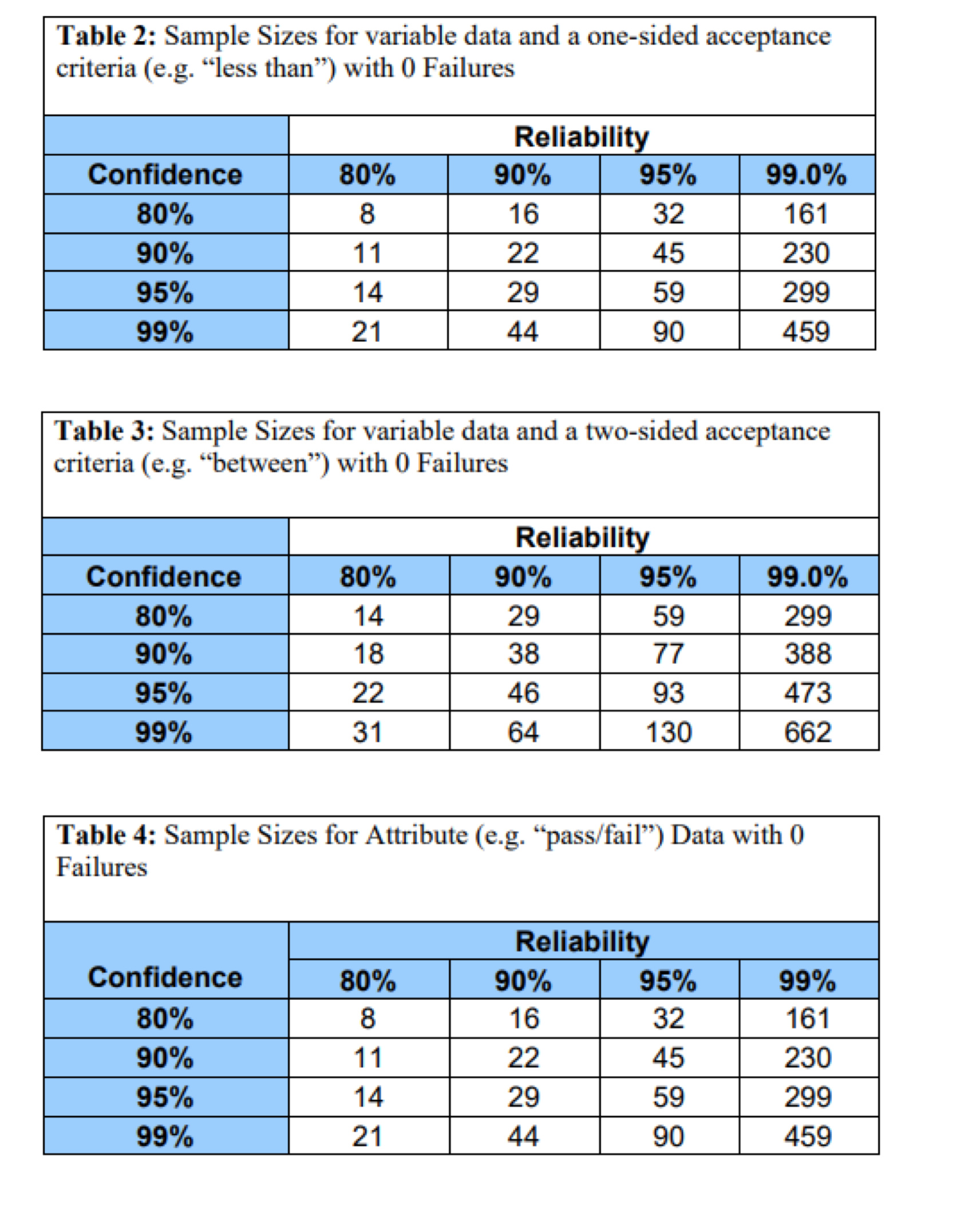
Here are some other useful links found online from:
1 Like
To add on, that sample quantity table is based on a Boolean distribution with 0 failures also called “testing to bogey”.
1 Like
@throwaway20210101 Oh wow, that’s pretty cool! Would you consider the above table to be generalized for selecting sample sizes broadly speaking as well?
Edit 1: Doing a bit of research and I found this pretty cool example:
- [Bogey Testing (Accelerated Life Testing)(http://www.engineeredsoftware.com/nasa/rt_bogey.htm#:~:text=Bogey%20testing%20requires%20the%20testing,2000%2C000%20kilometers%20of%20testing.)